Search the Community
Showing results for tags 'showcase'.
Found 18 results
-
I'll post some of my doom mods in this thread soon.
-
A SourceMod plugin that adds extra CT and T spawn points in Counter-Strike: Source and Counter-Strike: Global Offensive. This is useful for large servers that have to deal with maps with not enough map spawn points. NOTE - When an additional spawn point is being added, it uses the vector and angle from an already existing spawn point for that team. ConVars sm_ESP_spawns_t - Amount of spawn points to enforce on the T team (Default 32). sm_ESP_spawns_ct - Amount of spawn points to enforce on the CT team (Default 32). sm_ESP_teams - Which team to add additional spawn points for. 0 = Disabled, 1 = All Teams, 2 = Terrorist only, 3 = Counter-Terrorist only (Default 1). sm_ESP_course - Whether to enable course mode or not. If 1, when T or CT spawns are at 0, the opposite team will get double the spawn points (Default 1). sm_ESP_debug - Whether to enable debugging (Default 0). sm_ESP_auto - Whether to add spawn points when a ConVar is changed. If 1, will add the spawn points as soon as a ConVar is changed (Default 0). sm_ESP_mapstart_delay - The delay of the timer on map start to add in spawn points (Default 1.0). Commands sm_addspawns - Attempts to add spawn points. sm_getspawncount - Receives the current spawn count on each team. sm_listspawns - Lists the vectors and angles of each spawn point on each team. Please note a client may have issues outputting all of the details into their console. However, using the server console has been very consistent from what I've seen. Installation Copy the compiled ExtraSpawnPoints.smx file into the server's addons/sourcemod/plugins directory. For compiling from source, the source code is available at scripting/ExtraSpawnPoints.sp. To enable the plugin, either restart the map, server, or execute the following SourceMod command. sm plugins load ExtraSpawnPoints Credits @Christian GitHub Repository & Source Code ExtraSpawnPoints.sp ExtraSpawnPoints.smx
-
Tests I've performed converting C to Assembly. Basically testing performance for code I've made in C and whatnot! A small repository to store my findings with converting C code to Assembly code along with measuring performance between the different clang optimization levels. I'm starting to learn more about Assembly because I want to understand how programs work on a very low level so I can optimize it the best I can. I've made the following source files to test with. Two source files for copying eight bytes of data from one 8-bit array (8 bytes in size) to another. One source file uses a for loop to achieve this while the other uses the native memcpy() function. Two source files for comparing a variable to five values. One source file uses if and else if while the other uses a switch statement. A source file that copies a string and outputs it to stdout. Two source files testing a for loop along with seeing if there's a difference when specifying pragma #unroll x which should unroll the for loop and result in better performance in our case. I'll likely be adding more files to this repository as time goes on. Dumping Assembly Code I used clang to emit LLVM and create the .bc file with no optimizations by the compiler (the -O0 flag). An example may be found below. clang -c -emit-llvm -O0 -o asm/testO2.bc src/test.c Since we emit LLVM, we may use the llc command to dump the Assembly code under specific optimization levels. I dump both the native architecture's Assembly code and also Intel's Assembly code (these Assembly files are appended with _intel). Here's an example using optimization level 2 (notice the -O=2 flag in the llc command). # Native architecture's Assembly code. llc -filetype=asm -O=2 -o asm/testO2.s asm/testO2.bc # Intel Assembly code. llc -filetype=asm -O=2 -o asm/testO2_intel.s --x86-asm-syntax=intel asm/testO2.bc NOTE - I'd recommend using the scripts/genassembly.sh Bash script I made to generate Assembly code under optimization levels 0 (None) - 3 and both non-Intel and Intel architectures. The script only requires one argument which is the name of the source file in src/ without the file extension (.c). Also make sure to modify the ROOTDIR variable if you place the script outside of this repository's scripts/ directory. An example may be found below. ./genassembly.sh pointer Optimization Levels Clang's optimization levels may be found in its manual page (man clang). For reference, here are the levels. Code Generation Options -O0, -O1, -O2, -O3, -Ofast, -Os, -Oz, -Og, -O, -O4 Specify which optimization level to use: -O0 Means “no optimization”: this level compiles the fastest and generates the most debuggable code. -O1 Somewhere between -O0 and -O2. -O2 Moderate level of optimization which enables most opti‐ mizations. -O3 Like -O2, except that it enables optimizations that take longer to perform or that may generate larger code (in an attempt to make the program run faster). -Ofast Enables all the optimizations from -O3 along with other aggressive optimizations that may violate strict com‐ pliance with language standards. -Os Like -O2 with extra optimizations to reduce code size. -Oz Like -Os (and thus -O2), but reduces code size further. -Og Like -O1. In future versions, this option might disable different optimizations in order to improve debuggability. -O Equivalent to -O2. -O4 and higher Currently equivalent to -O3 You'll notice a lot of optimizations within the Assembly code from -O1 to -O3. System This was all tested on my Linux VM running virtio_net drivers and Ubuntu 20.04 Server. The Linux kernel the tests in asm/ were built with was 5.15.2-051502-generic. Credits @Christian GitHub Repository & Source Code
-
Examples of C programs using hashing functions from GNOME's GLib library. A repository I'm using to store my progress while learning GNOME's GLib library. Specifically hashing via ghash. Test Files GLib Structures (glib_structs.c) In this test, we have structures as keys and values (all integers). However, the total size for each the key and value exceeds 64-bits. We also use the g_int_hash hashing function (along with g_int_equal) which works fine. By default, the amount of entries it inserts and looks up is 5 (MAX_ENTRIES_DEFAULT). However, the first argument of the program determines how many entries to insert and lookup. Please look at the following example. ./build/glib_structs 20 The above (after building, of course) will output the following. dev@test02:~/glib-tests$ ./build/glib_structs 20 Successfully inserted entry! Key => 0:0:0:0 (0). Val => 0:0:0:0:0:0. Successfully inserted entry! Key => 300:3:600:90 (1). Val => 1:2:3:4:100000:10000000. Successfully inserted entry! Key => 600:6:1200:180 (2). Val => 2:4:6:8:200000:20000000. Successfully inserted entry! Key => 900:9:1800:270 (3). Val => 3:6:9:12:300000:30000000. Successfully inserted entry! Key => 1200:12:2400:360 (4). Val => 4:8:12:16:400000:40000000. Successfully inserted entry! Key => 1500:15:3000:450 (5). Val => 5:10:15:20:500000:50000000. Successfully inserted entry! Key => 1800:18:3600:540 (6). Val => 6:12:18:24:600000:60000000. Successfully inserted entry! Key => 2100:21:4200:630 (7). Val => 7:14:21:28:700000:70000000. Successfully inserted entry! Key => 2400:24:4800:720 (8). Val => 8:16:24:32:800000:80000000. Successfully inserted entry! Key => 2700:27:5400:810 (9). Val => 9:18:27:36:900000:90000000. Successfully inserted entry! Key => 3000:30:6000:900 (10). Val => 10:20:30:40:1000000:100000000. Successfully inserted entry! Key => 3300:33:6600:990 (11). Val => 11:22:33:44:1100000:110000000. Successfully inserted entry! Key => 3600:36:7200:1080 (12). Val => 12:24:36:48:1200000:120000000. Successfully inserted entry! Key => 3900:39:7800:1170 (13). Val => 13:26:39:52:1300000:130000000. Successfully inserted entry! Key => 4200:42:8400:1260 (14). Val => 14:28:42:56:1400000:140000000. Successfully inserted entry! Key => 4500:45:9000:1350 (15). Val => 15:30:45:60:1500000:150000000. Successfully inserted entry! Key => 4800:48:9600:1440 (16). Val => 16:32:48:64:1600000:160000000. Successfully inserted entry! Key => 5100:51:10200:1530 (17). Val => 17:34:51:68:1700000:170000000. Successfully inserted entry! Key => 5400:54:10800:1620 (18). Val => 18:36:54:72:1800000:180000000. Successfully inserted entry! Key => 5700:57:11400:1710 (19). Val => 19:38:57:76:1900000:190000000. Size of table is now 20 (entries). Lookup successful! Key => 0:0:0:0 (0). Val => 0:0:0:0:0:0. Lookup successful! Key => 300:3:600:90 (1). Val => 1:2:3:4:100000:10000000. Lookup successful! Key => 600:6:1200:180 (2). Val => 2:4:6:8:200000:20000000. Lookup successful! Key => 900:9:1800:270 (3). Val => 3:6:9:12:300000:30000000. Lookup successful! Key => 1200:12:2400:360 (4). Val => 4:8:12:16:400000:40000000. Lookup successful! Key => 1500:15:3000:450 (5). Val => 5:10:15:20:500000:50000000. Lookup successful! Key => 1800:18:3600:540 (6). Val => 6:12:18:24:600000:60000000. Lookup successful! Key => 2100:21:4200:630 (7). Val => 7:14:21:28:700000:70000000. Lookup successful! Key => 2400:24:4800:720 (8). Val => 8:16:24:32:800000:80000000. Lookup successful! Key => 2700:27:5400:810 (9). Val => 9:18:27:36:900000:90000000. Lookup successful! Key => 3000:30:6000:900 (10). Val => 10:20:30:40:1000000:100000000. Lookup successful! Key => 3300:33:6600:990 (11). Val => 11:22:33:44:1100000:110000000. Lookup successful! Key => 3600:36:7200:1080 (12). Val => 12:24:36:48:1200000:120000000. Lookup successful! Key => 3900:39:7800:1170 (13). Val => 13:26:39:52:1300000:130000000. Lookup successful! Key => 4200:42:8400:1260 (14). Val => 14:28:42:56:1400000:140000000. Lookup successful! Key => 4500:45:9000:1350 (15). Val => 15:30:45:60:1500000:150000000. Lookup successful! Key => 4800:48:9600:1440 (16). Val => 16:32:48:64:1600000:160000000. Lookup successful! Key => 5100:51:10200:1530 (17). Val => 17:34:51:68:1700000:170000000. Lookup successful! Key => 5400:54:10800:1620 (18). Val => 18:36:54:72:1800000:180000000. Lookup successful! Key => 5700:57:11400:1710 (19). Val => 19:38:57:76:1900000:190000000. Building You may use git and make to build this project. You will also need clang and libglib2.0. The following will do for Debian/Ubuntu systems. # Run apt update as root. sudo apt update # Install Make and build essentials. sudo apt install build-essential # Install Clang if it isn't installed already. sudo apt install clang # Install GLib 2.0 along with pkg-config (which is used for obtaining GLib's include paths and linker libraries). sudo apt install libglib2.0 pkg-config # Clone the repository. git clone https://github.com/gamemann/GLib-Tests.git # Change directory to GLib-Tests/. cd GLib-Tests/ # Run Make which will output executables into the build/ directory. make Credits @Christian GitHub Repository & Source Code
-
A small project that allows you to gather statistics (integers/counts) from files on the file system. This was designed for Linux. This is useful for retrieving the incoming/outgoing packets per second or incoming/outgoing bytes per second on a network interface. Building Program You can simply use make to build this program. The Makefile uses clang to compile the program. # (Debian/Ubuntu-based systems) apt-get install clang # (CentOS/Others) yum install devtoolset-7 llvm-toolset-7 llvm-toolset-7-clang-analyzer llvm-toolset-7-clang-tools-extra # Build the project. make You may use make install to copy the gstat executable to your $PATH via /usr/bin. Note - We use gstat instead of stat due to other common packages. Command Line Usage General command line usage can be found below. gstat [-i <interface> --pps --bps --path <path> -c <"kbps" or "mbps" or "gbps"> --custom <integer>] --pps => Set path to RX packet path. --bps => Set path to RX byte path. -p --path => Use count (integer) from a given path on file system. -i --dev => The name of the interface to use when setting --pps or --bps. -c --convert => Convert to either "kbps", "mbps", or "gbps". --custom => Divides the count value by this much before outputting to stdout. --interval => Use this interval (in microseconds) instead of one second. --count -n => Maximum amount of times to request the counter before stopping program (0 = no limit). --time -t => Time limit (in seconds) before stopping program (0 = no limit). Note - If you want to receive another counter such as outgoing (TX) packets, you can set the file to pull the count from with the -p (or --path) flag. For example. gstat --path /sys/class/net/ens18/statistics/tx_packets Credits @Christian GitHub Repository & Source Code
-
A program that calculates packet stats inside of an XDP program (support for both dropping and TX'ing the packet). As of right now, the stats are just the amount of packets and bytes (including per second). The stats are calculated to UDP packets with the destination port 27015 by default. You may adjust the port inside of src/include.h. If you comment out the TARGETPORT define with //, it will calculate stats for packets on all ports. Command Line Options There are two command line options for this program which may be found below. -i --interface => The interface name to attempt to attach the XDP program to (required). -t --time => How long to run the program for in seconds. -x --afxdp => Calculate packet counters inside of an AF_XDP program and drop or TX them. -r --tx => TX the packet instead of dropping it (supports both XDP and AF_XDP). -c --cores => If AF_XDP is specified, use this flag to override how many threads/AF_XDP sockets are spun up (keep in mind this should be the amount of RX queue you have since these bind to an individual RX queue). -s --skb => Force SKB mode. -o --offload => Try loading the XDP program in offload mode. TX Modes There are two modes and they must be adjusted inside of the source file. By default, an FIB lookup is performed inside of the XDP program and if a match is found, it will TX the packet + update the stats in the raw XDP or AF_XDP programs. Otherwise, the packet is dropped. The second mode simply switches the ethernet header's source and destination MAC address and TX's the packet back out. For performance reasons, I didn't include it as a command line option. Instead, you will need to go to src/xdp/raw_xdp_tx.c (for raw XDP) or src/af_xdp/raw_xdp_tx.c and comment out the #define FIBLOOKUP line by adding // in-front. For example: //#define FIBLOOKUP Building You may use the following to build the program. # Clone the repository and libbpf (with the --recursive flag). git clone --recursive https://github.com/gamemann/XDP-Stats.git # Change directory to the repository. cd XDP-Stats # Build the program. make # Install the program. The program is installed to /usr/bin/xdpstats sudo make install Credits @Christian GitHub Repository & Source Code
-
A personal tool using Python's Scrapy framework to scrape Best Buy's product pages for RTX 3080 TIs and notify if available/not sold out. My first project using Python's Scrapy framework. I'm using this project personally for a couple friends of mine and I. Basically, it scrapes a products listing page from BestBuy that lists RTX 3080 TIs. It scans each product and if the c-button-disable class doesn't exist within each entry (indicating it is not sold out and available), it will email a list of users from the settings.py file. It keeps each ID tracked in SQLite to make sure users don't get emailed more than once. Requirements The Scrapy framework is required and may be installed with the following. python3 -m pip install scrapy Settings Settings are configured in the src/bestbuy_parser/bestbuy_parser/settings.py file. The following are defaults. # General Scrapy settings. BOT_NAME = 'bestbuy_parser' SPIDER_MODULES = ['bestbuy_parser.spiders'] NEWSPIDER_MODULE = 'bestbuy_parser.spiders' TELNETCONSOLE_ENABLED = False LOG_LEVEL = 'ERROR' # The User Agent used to crawl. USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Best Buy Parser-specific settings. # The email's subject to send. MAIL_SUBJECT = "RTX 3080 TI In Stock On Best Buy!" # Where the email is coming from. MAIN_FROM = "[email protected]" # The email body. MAIL_BODY = '<html><body><ul><li><a href="https://www.bestbuy.com{link}">{name}</a></li><li>{price}</li></ul></body></html> Running The Program You must change the working directory to src/bestbuy_parser/bestbuy_parser via cd. Afterwards, you may run the following. python3 parse.py This will run the program until a keyboard interrupt. Systemd Service A systemd service is included in the systemd/ directory. It is assuming you cloned the repository into /usr/src (you will need to change the systemd file if this is not correct). You may install the systemd service via the following command as root (or ran with sudo). sudo make install Credits @Christian GitHub Repository & Source Code
-
A repository that includes common helper functions for writing applications in the DPDK. I will be using this for my future projects in the DPDK. This project includes helpful functions and global variables for developing applications using the DPDK. I am using this for my projects using the DPDK. A majority of this code comes from the l2fwd example from the DPDK's source files, but I rewrote all of the code to learn more from it and I tried adding as many comments as I could explaining what I understand from the code. I also highly organized the code and removed a lot of things I thought were unnecessary in developing my applications. I want to make clear that I am still new to the DPDK. While the helper functions and global variables in this project don't allow for in-depth configuration of the DPDK application, it is useful for general setups such as making packet generator programs or wanting to make a fast packet processing library where you're inspecting and manipulating packets. My main goal is to help other developers with the DPDK along with myself. From what I've experienced, learning the DPDK can be very overwhelming due to the amount of complexity it has. I mean, have you seen their programming documentation/guides here?! I'm just hoping to help other developers learn the DPDK. As time goes on and I learn more about the DPDK, I will add onto this project! My Other Projects Using DPDK Common I have other projects in the pipeline that'll use DPDK Common once I implement a few other things. However, here is the current list. Examples/Tests - A repository I'm using to store examples and tests of the DPDK while I learn it. The Custom Return Structure This project uses a custom return structure for functions returning values (non-void). The name of the structure is dpdkc_ret. struct dpdkc_ret { char *gen_msg; int err_num; int port_id; int rx_id; int tx_id; __u32 data; void *dataptr; }; With that said, the function dpdkc_check_ret(struct dpdkc_ret *ret) checks for an error in the structure and exits the application with debugging information if there is an error found (!= 0). Any data from the functions returning this structure should be stored in the data pointer. You will need to cast when using this data in the application since it is of type void *. Functions Including the src/dpdk_common.h header in a source or another header file will additionally include general header files from the DPDK. With that said, it will allow you to use the following functions which are a part of the DPDK Common project. /** * Initializes a DPDK Common result type and returns it with default values. * * @return The DPDK Common return structure (struct dpdkc_ret) with its default values. **/ struct dpdkc_ret dpdkc_ret_init(); /** * Parses the port mask argument and stores it in the enabled_port_mask global variable. * * @param arg A (const) pointer to the optarg variable from getopt.h. * * @return The DPDK Common return structure (struct dpdkc_ret). The port mask is stored in ret->data. **/ struct dpdkc_ret dpdkc_parse_arg_port_mask(const char *arg); /** * Parses the port pair config argument. * * @param arg A (const) pointer to the optarg variable from getopt.h. * * @return The DPDK Common return structure (struct dpdkc_ret). **/ struct dpdkc_ret dpdkc_parse_arg_port_pair_config(const char *arg); /** * Parses the queue number argument and stores it in the global variable(s). * * @param arg A (const) pointer to the optarg variable from getopt.h. * @param rx Whether this is a RX queue count. * @param tx Whether this is a TX queue count. * * @return The DPDK Common return structure (struct dpdkc_ret). The amount of queues is stored in ret->data. **/ struct dpdkc_ret dpdkc_parse_arg_queues(const char *arg, int rx, int tx) /** * Checks the port pair config after initialization. * * @return The DPDK Common return structure (struct dpdkc_ret). **/ struct dpdkc_ret dpdkc_check_port_pair_config(void); /** * Checks and prints the status of all running ports. * * @return Void **/ void dpdkc_check_link_status(); /** * Initializes the DPDK application's EAL. * * @param argc The argument count. * @param argv Pointer to arguments array. * * @return The DPDK Common return structure (struct dpdkc_ret). **/ struct dpdkc_ret dpdkc_eal_init(int argc, char **argv); /** * Retrieves the amount of ports available. * * @return The DPDK Common return structure (struct dpdkc_ret). Number of available ports are stored inside of ret->data. **/ struct dpdkc_ret dpdkc_get_nb_ports(); /** * Checks all port pairs. * * @return The DPDK Common return structure (struct dpdkc_ret). **/ struct dpdkc_ret dpdkc_check_port_pairs(); /** * Checks all ports against port mask. * * @return The DPDK Common return structure (struct dpdkc_ret). **/ struct dpdkc_ret dpdkc_ports_are_valid(); /** * Resets all destination ports. * * @return Void **/ void dpdkc_reset_dst_ports(); /** * Populates all destination ports. * * @return Void **/ void dpdkc_populate_dst_ports(); /** * Maps ports and queues to each l-core. * * @return The DPDK Common return structure (struct dpdkc_ret). **/ struct dpdkc_ret dpdkc_ports_queues_mapping(); /** * Creates the packet's mbuf pool. * * @return The DPDK Common return structure (struct dpdkc_ret). **/ struct dpdkc_ret dpdkc_create_mbuf(); /** * Initializes all ports and RX/TX queues. * * @param promisc If 1, promisc mode is turned on for all ports/devices. * @param rx_queues The amount of RX queues per port (recommend setting to 1). * @param tx_queues The amount of TX queues per port (recommend setting to 1). * * @return The DPDK Common return structure (struct dpdkc_ret). **/ struct dpdkc_ret dpdkc_ports_queues_init(int promisc, int rx_queues, int tx_queues); /** * Check if the number of available ports is above one. * * @return The DPDK Common return structure (struct dpdkc_ret). The amount of available ports is returned in ret->data. **/ struct dpdkc_ret dpdkc_ports_available(); /** * Retrieves the amount of l-cores that are enabled and stores it in nb_lcores variable. * * @return The DPDK Common return structure (struct dpdkc_ret). The amount of available ports is returned in ret->data. **/ struct dpdkc_ret dpdkc_get_available_lcore_count() /** * Launches the DPDK application and waits for all l-cores to exit. * * @param f A pointer to the function to launch on all l-cores when ran. * * @return Void **/ void dpdkc_launch_and_run(void *f); /** * Stops and removes all running ports. * * @return The DPDK Common return structure (struct dpdkc_ret). **/ struct dpdkc_ret dpdkc_port_stop_and_remove(); /** * Cleans up the DPDK application's EAL. * * @return The DPDK Common return structure (struct dpdkc_ret). **/ struct dpdkc_ret dpdkc_eal_cleanup(); /** * Checks error from dpdkc_ret structure and prints error along with exits if found. * * @return Void **/ void dpdkc_check_ret(struct dpdkc_ret *ret); The following function(s) are available if USE_HASH_TABLES is defined. /** * Removes the least recently used item from a regular hash table if the table exceeds max entries. * * @param tbl A pointer to the hash table. * @param max_entries The max entries in the table. * * @return 0 on success or -1 on error (failed to delete key from table). **/ int check_and_del_lru_from_hash_table(void *tbl, __u64 max_entries); Global Variables Additionally, there are useful global variables directed towards aspects of the program for the DPDK. However, these are prefixed with the extern tag within the src/dpdk_common.h header file allowing you to use them anywhere else assuming the file is included and the object file built from make is linked. // Variable to use for signals. volatile __u8 quit; // The RX and TX descriptor sizes (using defaults). __u16 nb_rxd = RTE_RX_DESC_DEFAULT; __u16 nb_txd = RTE_TX_DESC_DEFAULT; // The enabled port mask. __u32 enabled_port_mask = 0; // Port pair params array. struct port_pair_params port_pair_params_array[RTE_MAX_ETHPORTS / 2]; // Port pair params pointer. struct port_pair_params *port_pair_params; // The number of port pair parameters. __u16 nb_port_pair_params; // The port config. struct port_conf ports[RTE_MAX_ETHPORTS]; // The amount of RX ports per l-core. unsigned int rx_port_pl = 1; // The amount of TX ports per l-core. unsigned int tx_port_pl = 1; // The amount of RX queues per port. unsigned int rx_queue_pp = 1; // The amount of TX queues per port. unsigned int tx_queue_pp = 1; // The queue's lcore config. struct lcore_port_conf lcore_port_conf[RTE_MAX_LCORE]; // The buffer packet burst. unsigned int packet_burst_size = MAX_PCKT_BURST_DEFAULT; // The ethernet port's config to set. struct rte_eth_conf port_conf = { .rxmode = { .split_hdr_size = 1 }, .rxmode = { .mq_mode = RTE_ETH_MQ_TX_NONE } }; // A pointer to the mbuf_pool for packets. struct rte_mempool *pcktmbuf_pool = NULL; // The current port ID. __u16 port_id = 0; // Number of ports and ports available. __u16 nb_ports = 0; __u16 nb_ports_available = 0; // L-core ID. unsigned int lcore_id = 0; // Number of l-cores. unsigned int nb_lcores = 0; Credits @Christian GitHub Repository & Source Code
-
A small repository I will be using to store my progress and test programs from the DPDK, a kernel bypass library very useful for fast packet processing. The DPDK is perhaps one of the fastest libraries used with network packet processing. This repository uses my DPDK Common project in an effort to make things simpler. WARNING - I am still adding more examples as time goes on and I need to test new functionality/methods. Requirements The DPDK - Intel's Data Plane Development Kit which acts as a kernel bypass library which allows for fast network packet processing (one of the fastest libraries out there for packet processing). The DPDK Common - A project written by me aimed to make my DPDK projects simpler to setup/run. Building The DPDK If you want to build the DPDK using default options, the following should work assuming you have the requirements such as ninja and meson. # Clone the DPDK repository. git clone https://github.com/DPDK/dpdk.git # Change directory. cd dpdk/ # Use meson build. meson build # Change directory to build/. cd build # Run Ninja. ninja # Run Ninja install as root via sudo. sudo ninja install # Link libraries and such. sudo ldconfig All needed header files from the DPDK will be stored inside of /usr/local/include/. You may receive ninja and meson using the following. # Update via `apt`. sudo apt update # Install Python PIP (version 3). sudo apt install python3 python3-pip # Install meson. Pip3 is used because 'apt' has an outdated version of Meson usually. sudo pip3 install meson # Install Ninja. sudo apt install ninja-build Building The Source Files You may use git and make to build the source files inside of this repository. git clone --recursive https://github.com/gamemann/The-DPDK-Examples.git cd The-DPDK-Examples/ make Executables will be built inside of the build/ directory by default. EAL Parameters All DPDK applications in this repository supports DPDK's EAL paramters. These may be found here. This is useful for specifying the amount of l-cores and ports to configure for example. Examples Drop UDP Port 8080 (Tested And Working) In this DPDK application, any packets arriving on UDP destination port 8080 will be dropped. Otherwise, if the packet's ethernet header type is IPv4 or VLAN, it will swap the source/destination MAC and IP addresses along with the UDP source/destination ports then send the packet out the TX path (basically forwarding the packet from where it came). In additional to EAL parameters, the following is available specifically for this application. -p --portmask => The port mask to configure (e.g. 0xFFFF). -P --portmap => The port map to configure (in '(x, y),(b,z)' format). -q --queues => The amount of RX and TX queues to setup per port (default and recommended value is 1). -x --promisc => Whether to enable promiscuous on all enabled ports. -s --stats => If specified, will print real-time packet counter stats to stdout. Here's an example. ./dropudp8080 -l 0-1 -n 1 -- -q 1 -p 0xff -s Simple Layer 3 Forward (Tested And Working) In this DPDK application, a simple routing hash table is created with the key being the destination IP address and the value being the MAC address to forward to. Routes are read from the /etc/l3fwd/routes.txt file in the following format. <ip address> <mac address in xx:xx:xx:xx:xx:xx> The following is an example. 10.50.0.4 ae:21:14:4b:3a:6d 10.50.0.5 d6:45:f3:b1:a4:3d When a packet is processed, we ensure it is an IPv4 or VLAN packet (we offset the packet data by four bytes in this case so we can process the rest of the packet without issues). Afterwards, we perform a lookup with the destination IP being the key on the route hash table. If the lookup is successful, the source MAC address is replaced with the destination MAC address (packets will be going out the same port they arrive since we create a TX buffer and queue) and the destination MAC address is replaced with the MAC address the IP was assigned to from the routes file mentioned above. Otherwise, the packet is dropped and the packet dropped counter is incremented. In additional to EAL parameters, the following is available specifically for this application. -p --portmask => The port mask to configure (e.g. 0xFFFF). -P --portmap => The port map to configure (in '(x, y),(b,z)' format). -q --queues => The amount of RX and TX queues to setup per port (default and recommended value is 1). -x --promisc => Whether to enable promiscuous on all enabled ports. -s --stats => If specified, will print real-time packet counter stats to stdout. Here's an example. ./simple_l3fwd -l 0-1 -n 1 -- -q 1 -p 0xff -s Rate Limit (Tested And Working) In this application, if a source IP equals or exceeds the packets per second or bytes per second specified in the command line, the packets are dropped. Otherwise, the ethernet and IP addresses are swapped along with the TCP/UDP ports and the packet is forwarded back out the TX path. Packet stats are also included with the -s flag. The following command line options are supported. -p --portmask => The port mask to configure (e.g. 0xFFFF). -P --portmap => The port map to configure (in '(x, y),(b,z)' format). -q --queues => The amount of RX and TX queues to setup per port (default and recommended value is 1). -x --promisc => Whether to enable promiscuous on all enabled ports. -s --stats => If specified, will print real-time packet counter stats to stdout. --pps => The packets per second to limit each source IP to. --bps => The bytes per second to limit each source IP to. Here's an example: ./ratelimit -l 0-1 -n 1 -- -q 1 -p 0xff -s NOTE - This application supports LRU recycling via a custom function I made in the DPDK Common project, check_and_del_lru_from_hash_table(). Make sure to define USE_HASH_TABLES before including the DPDK Common header file when using this function. Least Recently Used Test (Tested And Working) This is a small application that implements a manual LRU method for hash tables. For a while I've been trying to get LRU tables to work from these libraries. However, I had zero success in actually getting the table initialized. Therefore, I decided to keep using these libraries instead and implement my own LRU functionality. I basically use the rte_hash_get_key_with_position() function to retrieve the oldest key to delete. However, it appears the new entry is inserted at the position that was most recently deleted so you have to keep incrementing the position value up to the max entries of the table. With that said, once the position value exceeds the maximum table entries, you need to set it back to 0. No command line options are needed, but EAL parameters are still supported. Though, they won't make a difference. Here's an example: ./ratelimit Credits @Christian GitHub Repository & Source Code
-
This is a GitHub Follow Bot made inside of a Django application. Management of the bot is done inside of Django's default admin center (/admin). The bot itself runs in the background of the Django application. The bot works as the following. Runs as a background task in the Django application. Management of bot is done in the Django application's web admin center. After installing, you must add a super user via Django (e.g. python3 manage.py createsuperuser). Navigate to the admin web center and add your target user (the user who will be following others) and seeders (users that start out the follow spread). After adding the users, add them to the target and seed user list. New/least updated users are parsed first up to the max users setting value followed by a random range wait scan time. A task is ran in the background for parsed users to make sure they're being followed by target users. Another task is ran in the background to retrieve target user's followers and if the Remove Following setting is on, it will automatically unfollow these specific users for the target users. Another task is ran that checks all users a target user is following and unfollows the user after x days (0 = doesn't unfollow). Each follow and unfollow is followed by a random range wait time which may be configured. To Do Develop a more randomized timing system including most likely active hours of the day. See if I can use something better in Django to alter general settings instead of relying on a table in the SQLite database. There are also issues with synchronization due to limitations with Django at this moment. Requirements The following Python models are required and I'd recommend Python version 3.8 or above since that's what I've tested with. django aiohttp You can install them like the below. # Python < 3 python -m pip install django python -m pip install aiohttp pip install django pip install aiohttp # Python >= 3 python3 -m pip install django python3 -m pip install aiohttp pip3 install django pip3 install aiohttp My Motives A few months ago, I discovered a few GitHub users following over 100K users who were obviously using bots. At first I was shocked because I thought GitHub was against massive following users, but after reading more into it, it appears they don't mind. This had me thinking what if I started following random users as well. Some of these users had a single GitHub.io project that received a lot of attention and I'd assume it's from all the users they were following. I decided to try this. I wanted to see if it'd help me connect with other developers and it certainly did/has! Personally, I haven't used a bot to achieve this, I was actually going through lists of followers from other accounts and following random users. As you'd expect, this completely cluttered my home page, but it also allowed me to discover new projects which was neat in my opinion. While this is technically 'spam', the good thing I've noticed is it certainly doesn't impact the user I'm following much other than adding a single line in their home page stating I'm following them (or them receiving an email stating this if they have that on). Though, I could see this becoming annoying if many people/bots started doing it (perhaps GitHub could add a user setting that has a maximum following count of a user who can follow them or receive notifications when the user follows). I actually think it's neat this is allowed so far because it allows others to discover your projects. Since I have quite a few networking projects on this account, I've had some people reach out who I followed stating they found my projects neat because they aren't into that field. I also wouldn't support empty profiles made just for the purpose of mass following. USE AT YOUR OWN RISK Even though it appears GitHub doesn't mind users massive following others (which I again, support), this is still considered a spam tactic and it is still technically against the rules. Therefore, please use this tool at your own risk. I'm not even going to be using it myself because I do enjoy manually following users. I made this project to learn more about Python. Settings Inside of the web interface, a settings model should be visible. The following settings should be inserted. enabled - Whether to enable the bot or not (should be "1" or "0"). max_scan_users - The maximum users to parse at once before waiting for scan time. wait_time_follow_min - The minimum number of seconds to wait after following or unfollowing a user. wait_time_follow_max - The maximum number of seconds to wait after following or unfollowing a user. wait_time_list_min - The minimum number of seconds to wait after parsing a user's followers page. wait_time_list_max - The maximum number of seconds to wait after parsing a user's followers page. scan_time_min - The minimum number of seconds to wait after parsing a batch of users. scan_time_max - The maximum number of seconds to wait after parsing a batch of users. verbose - Verbose level for stdout (see levels below). + Notification when a target user follows another user. + Notification when a target user unfollows a user due to being on the follower list or purge. + Notification when users are automatically created from follow spread. user_agent - The User Agent used to connect to the GitHub API. seed - Whether to seed (add any existing user's followers to the user list). seed_min_free - If above 0 and seeding is enabled, seeding will only occur when the amount of new users (users who haven't been followed by any target users) is below this value. max_api_fails - The max amount of GitHub API fails before stopping the bot for a period of time based off of below (0 = disable). lockout_wait_min - When the amount of fails exceeds max API fails, it will wait this time minimum in minutes until starting up again. lockout_wait_max - When the amount of fails exceeds max API fails, it will wait this time maximum in minutes until starting up again. seed_max_pages - The max amount of pages to seed from with each user parse when looking for new users (seeding). Installation Installation should be performed like a regular Django application. This application uses SQLite as the database. You can read more about Django here. I would recommend the following commands. # Make sure Django and aiohttp are installed for this user. # Clone repository. git clone https://github.com/gamemann/GitHub-Follower-Bot.git # Change directory to Django application. cd GitHub-Follower-Bot/src/github_follower # Migrate database. python3 manage.py migrate # Run the development server on any IP (0.0.0.0) as port 8000. # NOTE - If you don't want to expose the application publicly, bind it to a LAN IP instead (e.g. 10.50.0.4:8000 instead 0f 0.0.0.0:8000). python3 manage.py runserver 0.0.0.0:8000 # Create super user for admin web interface. python3 manage.py createsuperuser The web interface should be located at http://<host/ip>:<port>. For example. http://localhost:8000 While you could technically run the Django application's development server for this bot since only the settings are configured through there, Django recommends reading this for production use. FAQ Why did you choose Django to use as an interface? While settings could have been configured on the host itself, I wanted an interface that was easily accessible from anywhere. The best thing for this would be a website in my opinion. Most of my experience is with Django which is why I chose that project. Credits @Christian GitHub Repository & Source Code
-
 List of Open Source Software: Peer To Peer: Defined Networking / Slack Nebula: Information: Written In Golang Use Case: best for server-to-server and server-to-network infrastructure GitHub: https://github.com/slackhq/nebula Website: https://www.defined.net/ Tailscale: Information: Uses WireGuard and written In Golang Use Case: best for user/server-to-server and user/server-to-network GitHub: https://github.com/tailscale/tailscale Website: https://tailscale.com/ ZeroTier: Information: Written In C/C++ Use Case: best for user-to-user or user-to-server GitHub: https://github.com/zerotier/ZeroTierOne Website: https://www.zerotier.com/ Nebula REST API: (Management API for Deploying Nebula) GitHub: https://github.com/elestio/nebula-rest-api Headscale: (For Tailscale Self-Hosting) GitHub: https://github.com/juanfont/headscale VPNs: Pritunl: Information: OpenVPN Based and written In Python Use Case: best for user-to-user or user-to-network, and supports high-availability. GitHub: https://github.com/pritunl/pritunl Website: https://pritunl.com/ SoftEther: Use Case: best for user-to-user or user-to-network GitHub: https://github.com/SoftEtherVPN/SoftEtherVPN/ Website: https://www.softether.org/ Tutorials & Information: About Nebula: https://slack.engineering/introducing-nebula-the-open-source-global-overlay-network-from-slack/ Slack Nebula is production ready with support to saturate 10+Gbps links as tested by Slack in production.
List of Open Source Software: Peer To Peer: Defined Networking / Slack Nebula: Information: Written In Golang Use Case: best for server-to-server and server-to-network infrastructure GitHub: https://github.com/slackhq/nebula Website: https://www.defined.net/ Tailscale: Information: Uses WireGuard and written In Golang Use Case: best for user/server-to-server and user/server-to-network GitHub: https://github.com/tailscale/tailscale Website: https://tailscale.com/ ZeroTier: Information: Written In C/C++ Use Case: best for user-to-user or user-to-server GitHub: https://github.com/zerotier/ZeroTierOne Website: https://www.zerotier.com/ Nebula REST API: (Management API for Deploying Nebula) GitHub: https://github.com/elestio/nebula-rest-api Headscale: (For Tailscale Self-Hosting) GitHub: https://github.com/juanfont/headscale VPNs: Pritunl: Information: OpenVPN Based and written In Python Use Case: best for user-to-user or user-to-network, and supports high-availability. GitHub: https://github.com/pritunl/pritunl Website: https://pritunl.com/ SoftEther: Use Case: best for user-to-user or user-to-network GitHub: https://github.com/SoftEtherVPN/SoftEtherVPN/ Website: https://www.softether.org/ Tutorials & Information: About Nebula: https://slack.engineering/introducing-nebula-the-open-source-global-overlay-network-from-slack/ Slack Nebula is production ready with support to saturate 10+Gbps links as tested by Slack in production. -
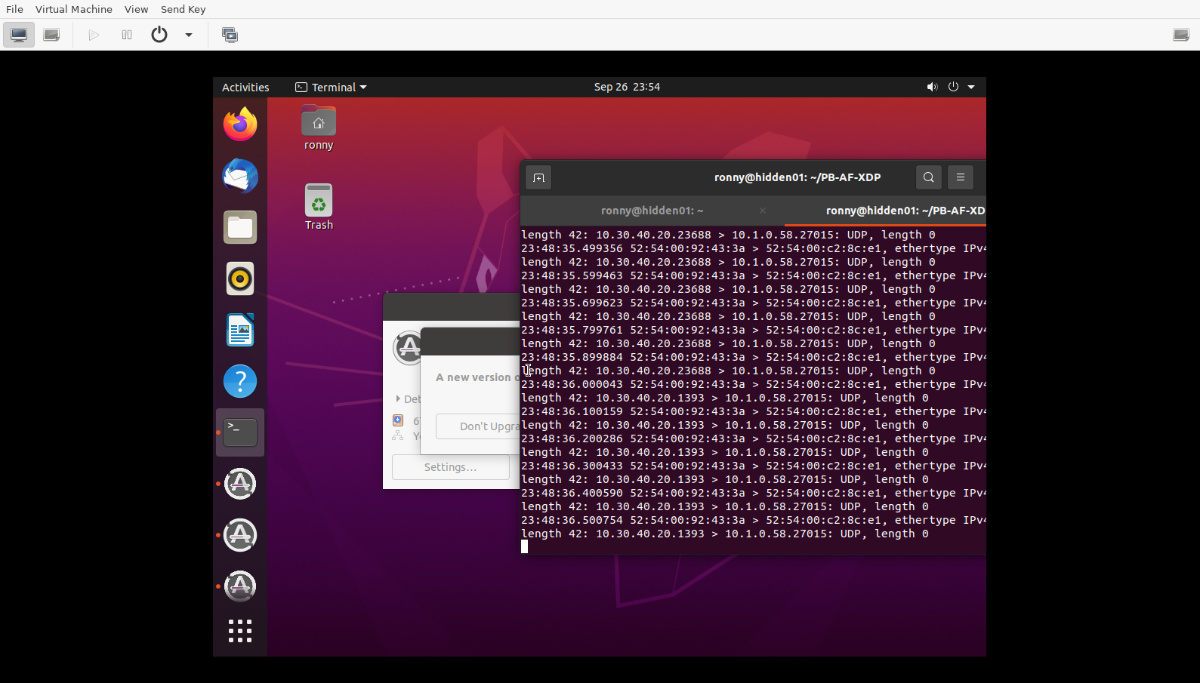
 Heya everyone! I am going to be showing you how to launch a simple DoS attack to a target host along with how to block the attack on the target's side. Learning the basic concepts of a (D)DoS attack is very beneficial, especially when hosting a modded server, community website/project, or just wanting to get involved in the Cyber Security field. With that said, I do NOT support using this guide and its tools maliciously or as part of a targeted attack. The following guide and tools involved were created for educational purposes. I am also going to show you how to block/drop the attack as well. Firstly, this tutorial requires basic knowledge of Linux and networking. We are also going to be using tools created by myself called Packet Batch (for the DoS attacks) and XDP Firewall (for dropping packets as fast as possible). Packet Batch is a collection of high-performant network traffic generation tools made in C. They utilize very fast network libraries and sockets to generate the most traffic and packets possible depending on the configuration. When you use the tool from multiple sources to the same target, it is considered a (D)DoS attack instead of DoS attack. Network Setup & Prerequisites A Linux server you're installing Packet Batch host. A target host; Should be a server within your LAN and to prevent overloading your router unless if you set bandwidth limits in Packet Batch, should be on the same machine via VMs. The local host's interface name which can be retrieved via ip a or ifconfig. The target host's IP and MAC address so you can bypass your router (not required typically if you want to send packets through your router). I'm personally using a hidden VM that I actually expose in this post, but I don't care for releasing since I only used it to browse Hack Forums lol (I made a hidden VM with the name "Ronny" back a long time ago). Installing Packet Batch Installing Packet Batch isn't too difficult since I provided a Makefile for each version that allows you to execute sudo make && sudo make install to easily build and install the project. The issue here is that we do use third-party libraries such as libyaml and a lot of times those third-party libraries and other's Linux kernel/distro don't play along. I'm testing this on Ubuntu 20.04 (retrieved via cat /etc/*-release) and kernel 5.4.0-122-generic (retrieved via uname -r). ➜ ~ cat /etc/*-release DISTRIB_ID=Ubuntu DISTRIB_RELEASE=20.04 DISTRIB_CODENAME=focal DISTRIB_DESCRIPTION="Ubuntu 20.04.5 LTS" NAME="Ubuntu" VERSION="20.04.5 LTS (Focal Fossa)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 20.04.5 LTS" VERSION_ID="20.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=focal UBUNTU_CODENAME=focal ➜ ~ uname -r 5.4.0-122-generic What Version Of Packet Batch Should I Use? There are three versions of Packet Batch. Versions include Standard, AF_XDP, and the DPDK. In this guide, we're going to be using the Standard version because other versions either require a more recent kernel or the DPDK which is a kernel-bypass library that only supports certain hardware (including the virtio_net driver). Building The Project You can read this section on the Standard repository showing how to build and install the version. There's also a video I made a while back below. # Clone this repository along with its submodules. git clone --recursive https://github.com/Packet-Batch/PB-Standard.git # Install build essentials/tools and needed libaries for LibYAML. sudo apt install build-essential clang autoconf libtool # Change the current working directory to PB-Standard/. cd PB-Standard/ # Make and install (must be ran as root via sudo or root user itself). sudo make sudo make install Launching The DoS Attack Unfortunately, the current version of Packet Batch doesn't support easily configurable parameters when trying to limit the amount of traffic and packets you send. This will be supported in the future, but for today we're going to use some math to determine this. With that said, we're going to be using one CPU thread for this, but if you want to send as much traffic as possible, I'd recommend multiple threads or just leaving it out of the command line which calculates the maximum amount of threads/cores automatically. We will also be launching an attack using the UDP protocol on port 27015 (used for many game servers on the Source Engine). We're going to send 10,000 packets per second to the target host. Our source port will be randomly generated, but you may set it statically if you'd like. The source MAC address is automatically retrieved via system functions on Linux, but you can override this if you'd like. MAC address format is in hexadecimal, "xx:xx:xx:xx:xx:xx". There will be no additional payload as well, UDP data's length will be 0 bytes. Here are the command line options we're going to be using. We're also going to be using the -z flag to allow command-line functionality and overriding the first sequence's values. --interface => The interface to send out of. --time => How many seconds to run the sequence for maximum. --delay => The delay in-between sending packets on each thread. --threads => The amount of threads and sockets to spawn (0 = CPU count). --l4csum => Whether to calculate the layer-4 checksum (TCP, UDP, and ICMP) (0/1). --dstmac => The ethernet destination MAC address to use. --srcip => The source IP. --dstip => The destination IP. --protocol => The protocol to use (TCP, UDP, or ICMP). --l3csum => Whether to calculate the IP header checksum or not (0/1). --udstport => The UDP destination port. Most of the above should be self-explanatory. However, I want to note some other things. Delay This is the delay between sending packets in nanoseconds for each thread. Since we're using one thread, this allows us to precisely calculate without doing additional math. One packet per second = 1e9 (1,000,000,000). Now we must divide the amount of nanoseconds by how many packets we want to send per second. So let's choose 10,000 which results in 100,000 (value => 100000). Layer 3 and 4 Checksums These should be automatically calculated unless if you know what you're doing. We set these to the value 1. Now let's build the command to send from our local host. sudo pcktbatch -z --interface "<iname>" --time 10 --delay 100000 --threads 1 --l3csum 1 --l4csum 1 --dstmac "<dmac>" --srcip "<sip>" --dstip "<dip>" --protocol UDP --udstport 27015 While launching the attack, on the target's server, you can run a packet capture such as the following for Linux. For Windows, you may use Wireshark. tcpdump -i any udp and port 27015 -nne Here is my local LAN environment's command. sudo pcktbatch -z --interface "enp1s0" --time 10 --delay 100000 --threads 1 --l3csum 1 --l4csum 1 --dstmac "52:54:00:c2:8c:e1" --srcip "10.30.40.20" --dstip "10.1.0.58" --protocol UDP --udstport 27015 Please note you can technically use any source IP address, mine in this case is spoofed. As long as you don't have any providers and upstreams with uRPF filtering for example, you shouldn't have an issue with this. Here's our packet dump via tcpdump on the target host ? I'd recommend messing around with settings and you can technically launch many type of attacks using this tool in protocols such as UDP, TCP, and ICMP. It's really beneficial knowing how to do this from a security standpoint so you can test your network filters. Blocking & Dropping The Attack Now that you know how to launch a simple UDP attack, now it's time to figure out how to block the attack. Thankfully, since this is a stateless attack, it is much easier to drop the attack than launch it. However, when we're talking stateful and layer-7 filters, I personally have to say making those are harder than launching complex attacks. Attack Characteristics There are a lot of characteristics of a network packet you may look for using tools such as tcpdump or Wireshark. However, since we've launched a simple stateless attack, it's quite easy to drop these packets. For a LAN setup, this would be fine but for a production server, you have to keep in-mind dropping malicious traffic from a legitimate attack will be harder and you're limited to your NIC's capacity which is typically 1 gbps. 1 gbps is considered very low network capacity which is why it's recommended to use hosting providers that have the fiber and hardware capacities to support up to tbps of bandwidth per second. Let's analyze the traffic and determine what we could drop statically. The source IP since it always stays the same. The UDP length is 0 bytes. Depending on the application, it may not normally send empty UDP packets so you can drop based off of this. The first item above is the best way to drop the traffic. However, many applications also don't send empty UDP packets. There are also other characteristics that may stay static as well such as the IP header's TTL, payload length, and more. However, for now, I'm keeping it simple. Dropping Via IPTables IPTables is a great tool to drop traffic with on Linux. However, there are faster tools such as my XDP Firewall that utilizes the XDP hook within the Linux kernel instead of the hook IPTables utilize (which occurs much later, therefore, slower). The following command would drop any traffic in the INPUT chain which is what we want to use for dropping traffic in this case. We will be dropping by IP as seen below. sudo iptables -A INPUT -s 10.38.40.20 -j DROP You can confirm the rule was created with the following command. iptables -L -n -v You can launch the attack again and watch the pckts and bytes counters increment. Dropping Via XDP Firewall As stated above, XDP Firewall is a tool I made and can drop traffic a lot faster than TC Filter (Traffic Control), NFTables, and IPTables. Please read the above repository on GitHub for building and installing. Afterwards, you may use the following config to drop the attack. /etc/xdpfw/xdpfw.conf interface = "<iname>"; updatetime = 15; filters = ( { enabled = true, action = 0, srcip = "10.38.40.20" } ); You may then run the tool as root via the below. sudo xdpfw Conclusion In this guide we learned how to use Packet Batch's Standard version to launch a simple UDP DoS attack at 10K packets per second and how to drop the traffic via IPTables or using my XDP Firewall tool. I hope this helps anybody getting into network and cyber security ? If you have any questions or feedback, please feel free to post in this thread! Thank you for your time!
Heya everyone! I am going to be showing you how to launch a simple DoS attack to a target host along with how to block the attack on the target's side. Learning the basic concepts of a (D)DoS attack is very beneficial, especially when hosting a modded server, community website/project, or just wanting to get involved in the Cyber Security field. With that said, I do NOT support using this guide and its tools maliciously or as part of a targeted attack. The following guide and tools involved were created for educational purposes. I am also going to show you how to block/drop the attack as well. Firstly, this tutorial requires basic knowledge of Linux and networking. We are also going to be using tools created by myself called Packet Batch (for the DoS attacks) and XDP Firewall (for dropping packets as fast as possible). Packet Batch is a collection of high-performant network traffic generation tools made in C. They utilize very fast network libraries and sockets to generate the most traffic and packets possible depending on the configuration. When you use the tool from multiple sources to the same target, it is considered a (D)DoS attack instead of DoS attack. Network Setup & Prerequisites A Linux server you're installing Packet Batch host. A target host; Should be a server within your LAN and to prevent overloading your router unless if you set bandwidth limits in Packet Batch, should be on the same machine via VMs. The local host's interface name which can be retrieved via ip a or ifconfig. The target host's IP and MAC address so you can bypass your router (not required typically if you want to send packets through your router). I'm personally using a hidden VM that I actually expose in this post, but I don't care for releasing since I only used it to browse Hack Forums lol (I made a hidden VM with the name "Ronny" back a long time ago). Installing Packet Batch Installing Packet Batch isn't too difficult since I provided a Makefile for each version that allows you to execute sudo make && sudo make install to easily build and install the project. The issue here is that we do use third-party libraries such as libyaml and a lot of times those third-party libraries and other's Linux kernel/distro don't play along. I'm testing this on Ubuntu 20.04 (retrieved via cat /etc/*-release) and kernel 5.4.0-122-generic (retrieved via uname -r). ➜ ~ cat /etc/*-release DISTRIB_ID=Ubuntu DISTRIB_RELEASE=20.04 DISTRIB_CODENAME=focal DISTRIB_DESCRIPTION="Ubuntu 20.04.5 LTS" NAME="Ubuntu" VERSION="20.04.5 LTS (Focal Fossa)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 20.04.5 LTS" VERSION_ID="20.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=focal UBUNTU_CODENAME=focal ➜ ~ uname -r 5.4.0-122-generic What Version Of Packet Batch Should I Use? There are three versions of Packet Batch. Versions include Standard, AF_XDP, and the DPDK. In this guide, we're going to be using the Standard version because other versions either require a more recent kernel or the DPDK which is a kernel-bypass library that only supports certain hardware (including the virtio_net driver). Building The Project You can read this section on the Standard repository showing how to build and install the version. There's also a video I made a while back below. # Clone this repository along with its submodules. git clone --recursive https://github.com/Packet-Batch/PB-Standard.git # Install build essentials/tools and needed libaries for LibYAML. sudo apt install build-essential clang autoconf libtool # Change the current working directory to PB-Standard/. cd PB-Standard/ # Make and install (must be ran as root via sudo or root user itself). sudo make sudo make install Launching The DoS Attack Unfortunately, the current version of Packet Batch doesn't support easily configurable parameters when trying to limit the amount of traffic and packets you send. This will be supported in the future, but for today we're going to use some math to determine this. With that said, we're going to be using one CPU thread for this, but if you want to send as much traffic as possible, I'd recommend multiple threads or just leaving it out of the command line which calculates the maximum amount of threads/cores automatically. We will also be launching an attack using the UDP protocol on port 27015 (used for many game servers on the Source Engine). We're going to send 10,000 packets per second to the target host. Our source port will be randomly generated, but you may set it statically if you'd like. The source MAC address is automatically retrieved via system functions on Linux, but you can override this if you'd like. MAC address format is in hexadecimal, "xx:xx:xx:xx:xx:xx". There will be no additional payload as well, UDP data's length will be 0 bytes. Here are the command line options we're going to be using. We're also going to be using the -z flag to allow command-line functionality and overriding the first sequence's values. --interface => The interface to send out of. --time => How many seconds to run the sequence for maximum. --delay => The delay in-between sending packets on each thread. --threads => The amount of threads and sockets to spawn (0 = CPU count). --l4csum => Whether to calculate the layer-4 checksum (TCP, UDP, and ICMP) (0/1). --dstmac => The ethernet destination MAC address to use. --srcip => The source IP. --dstip => The destination IP. --protocol => The protocol to use (TCP, UDP, or ICMP). --l3csum => Whether to calculate the IP header checksum or not (0/1). --udstport => The UDP destination port. Most of the above should be self-explanatory. However, I want to note some other things. Delay This is the delay between sending packets in nanoseconds for each thread. Since we're using one thread, this allows us to precisely calculate without doing additional math. One packet per second = 1e9 (1,000,000,000). Now we must divide the amount of nanoseconds by how many packets we want to send per second. So let's choose 10,000 which results in 100,000 (value => 100000). Layer 3 and 4 Checksums These should be automatically calculated unless if you know what you're doing. We set these to the value 1. Now let's build the command to send from our local host. sudo pcktbatch -z --interface "<iname>" --time 10 --delay 100000 --threads 1 --l3csum 1 --l4csum 1 --dstmac "<dmac>" --srcip "<sip>" --dstip "<dip>" --protocol UDP --udstport 27015 While launching the attack, on the target's server, you can run a packet capture such as the following for Linux. For Windows, you may use Wireshark. tcpdump -i any udp and port 27015 -nne Here is my local LAN environment's command. sudo pcktbatch -z --interface "enp1s0" --time 10 --delay 100000 --threads 1 --l3csum 1 --l4csum 1 --dstmac "52:54:00:c2:8c:e1" --srcip "10.30.40.20" --dstip "10.1.0.58" --protocol UDP --udstport 27015 Please note you can technically use any source IP address, mine in this case is spoofed. As long as you don't have any providers and upstreams with uRPF filtering for example, you shouldn't have an issue with this. Here's our packet dump via tcpdump on the target host ? I'd recommend messing around with settings and you can technically launch many type of attacks using this tool in protocols such as UDP, TCP, and ICMP. It's really beneficial knowing how to do this from a security standpoint so you can test your network filters. Blocking & Dropping The Attack Now that you know how to launch a simple UDP attack, now it's time to figure out how to block the attack. Thankfully, since this is a stateless attack, it is much easier to drop the attack than launch it. However, when we're talking stateful and layer-7 filters, I personally have to say making those are harder than launching complex attacks. Attack Characteristics There are a lot of characteristics of a network packet you may look for using tools such as tcpdump or Wireshark. However, since we've launched a simple stateless attack, it's quite easy to drop these packets. For a LAN setup, this would be fine but for a production server, you have to keep in-mind dropping malicious traffic from a legitimate attack will be harder and you're limited to your NIC's capacity which is typically 1 gbps. 1 gbps is considered very low network capacity which is why it's recommended to use hosting providers that have the fiber and hardware capacities to support up to tbps of bandwidth per second. Let's analyze the traffic and determine what we could drop statically. The source IP since it always stays the same. The UDP length is 0 bytes. Depending on the application, it may not normally send empty UDP packets so you can drop based off of this. The first item above is the best way to drop the traffic. However, many applications also don't send empty UDP packets. There are also other characteristics that may stay static as well such as the IP header's TTL, payload length, and more. However, for now, I'm keeping it simple. Dropping Via IPTables IPTables is a great tool to drop traffic with on Linux. However, there are faster tools such as my XDP Firewall that utilizes the XDP hook within the Linux kernel instead of the hook IPTables utilize (which occurs much later, therefore, slower). The following command would drop any traffic in the INPUT chain which is what we want to use for dropping traffic in this case. We will be dropping by IP as seen below. sudo iptables -A INPUT -s 10.38.40.20 -j DROP You can confirm the rule was created with the following command. iptables -L -n -v You can launch the attack again and watch the pckts and bytes counters increment. Dropping Via XDP Firewall As stated above, XDP Firewall is a tool I made and can drop traffic a lot faster than TC Filter (Traffic Control), NFTables, and IPTables. Please read the above repository on GitHub for building and installing. Afterwards, you may use the following config to drop the attack. /etc/xdpfw/xdpfw.conf interface = "<iname>"; updatetime = 15; filters = ( { enabled = true, action = 0, srcip = "10.38.40.20" } ); You may then run the tool as root via the below. sudo xdpfw Conclusion In this guide we learned how to use Packet Batch's Standard version to launch a simple UDP DoS attack at 10K packets per second and how to drop the traffic via IPTables or using my XDP Firewall tool. I hope this helps anybody getting into network and cyber security ? If you have any questions or feedback, please feel free to post in this thread! Thank you for your time!
-
A collection of high-performing applications which act as pen-testing/DoS (Denial-of-Service) tools. Each tool utilizes a different network library/socket type for flexibility with a goal to generate the most network traffic as possible depending on the configuration. I do NOT support using these tools maliciously. I made these tools for educational purposes and hope others may learn from them. Please use these tools responsibly. With that said, if these tools are launched from multiple sources to the same network/IP, it is considered a DDoS (Distributed Denial-of-Service) attack. You may customize a lot of the packet's contents (layer 2/3/4 headers and payload) and launch different types of attacks at once or in a chain via sequences. The following are also supported. Randomized source IPs via CIDR ranges. Randomized payload length (within a minimum and maximum range). UDP, TCP, and ICMP layer 4 protocols supported. Optional layer 3 and 4 checksum calculation in the event you want the NIC's hardware to calculate checksums for the outgoing packets. NOTE - This project was inspired by my previous Packet Sequence project. Packet Sequence only supported AF_PACKETv3 Linux sockets. However, in an effort to simplify code, I decided to make a new organization and project which'll support special versions for AF_XDP Linux sockets and the DPDK which should be a lot faster than the standard version with the exception of no TCP cooked sockets support. Packet Batch Applications/Versions There are three versions of Packet Batch, please read the following. Standard - Uses AF_PACKETv3 sockets and supports TCP cooked sockets for easy TCP connection establishing. AF_XDP - Uses AF_XDP sockets which is faster than AF_PACKETv3, but doesn't support TCP cooked sockets. DPDK - Uses the DPDK which is faster than all other versions, but since the DPDK is a kernel-bypass library, it is harder to setup and only supports certain hardware. The tool also doesn't support TCP cooked sockets. Dependencies LibYAML - Used for parsing config files using the YAML syntax. YAML Configuration If you want to use Packet Batch for more than one sequence, you will need to specify sequences inside of a config file using the YAML syntax. Please see the following for an explanation. # The interface to use when sending packets. interface: NULL sequences: seq01: # An array of other configs to include before this sequence. WARNING - If this is used, you must write this at the beginning of the sequence like this example. Otherwise, unexpected results will occur (e.g. the current sequence will be overwritten). This is empty by default and only showing as an example. includes: - /etc/pcktbatch/include_one.yaml - /etc/pcktbatch/include_two.yaml # If set, will use a specific interface for this sequence. Otherwise, uses the default interface specified at the beginning of the config. interface: NULL # If true, future sequences will wait until this one finishes before executing. block: true # The maximum packets this sequence can produce before terminating. count: 0 # The maximum bytes this sequence can produce before terminating. data: 0 # How long in seconds this sequence can go on before terminating. time: 0 # The amount of threads to spawn with this sequence. If this is set to 0, it will use the CPU count (recommended). threads: 0 # The delay between sending packets on each thread in microseconds. delay: 1000000 # If true, even if 'count' is set to 0, the program will keep a packet counter inside of each thread. As of right now, a timestamp (in seconds) and a packet counter is used to generate a seed for randomness within the packet. If you want true randomness with every packet and not with each second, it is recommended you set this to true. Otherwise, this may result in better performance if kept set to false. trackcount: false # Ethernet header options. eth: # The source MAC address. If not set, the program will retrieve the MAC address of the interface we are binding to (the "interface" value). srcmac: NULL # The destination MAC address. If not set, the program will retrieve the default gateway's MAC address. dstmac: NULL # IP header options. ip: # Source ranges in CIDR format. By default, these aren't set, but I wanted to show an example anyways. These will be used if 'srcip' is not set. ranges: - 172.16.0.0/16 - 10.60.0.0/24 - 192.168.30.0/24 # The source IPv4 address. If not set, you will need to specify source ranges in CIDR format like the above. If no source IP ranges are set, a warning will be outputted to `stderr` and 127.0.0.1 (localhost) will be used. srcip: NULL # The destination IPv4 address. If not set, the program will output an error. We require a value here. Otherwise, the program will shutdown. dstip: NULL # The IP protocol to use. At the moment, the only supported values are udp, tcp, and icmp. protocol: udp # The Type-Of-Service field (8-bit integer). tos: 0 # The Time-To-Live field (8-bit integer). For static, set min and max to the same value. ttl: # Each packet generated will pick a random TTL. This is the minimum value within that range. min: 0 # Each packet generated will pick a random TTL This is the maximum value within that range. max: 0 # The ID field. For static, set min and max to the same value. id: # Each packet generated will pick a random ID. This is the minimum value within that range. min: 0 # Each packet generated will pick a random ID. This is the maximum value within that range. max: 0 # If true, we will calculate the IP header's checksum. If your NIC supports checksum offload with the IP header, disabling this option may improve performance within the program. csum: true # If true, we will calculate the layer-4 protocol checksum (UDP, TCP, and ICMP). l4csum: true # UDP header options. udp: # The source port. If 0, the program will generate a random number between 1 and 65535. srcport: 0 # The destination port. If 0, the program will generate a random number between 1 and 65535. dstport: 0 # TCP header options. tcp: # The source port. If 0, the program will generate a random number between 1 and 65535. srcport: 0 # The destination port. If 0, the program will generate a random number between 1 and 65535. dstport: 0 # If true, will set the TCP SYN flag. syn: false # If true, will set the TCP ACK flag. ack: false # If true, will set the TCP PSH flag. psh: false # If true, will set the TCP RST flag. rst: false # If true, will set the TCP FIN flag. fin: false # If true, will set the TCP URG flag. urg: false # If true, the socket will be setup as a cooked TCP socket. This establishes the three-way TCP handshake. WARNING - This makes the program ignore all of the headers. The only relevant information is the payload, destination IP, and port (must be static) when this is set to true. # NOTE - This is only supported for the standard version. usesocket: false # ICMP header options. icmp: # The code to use with the ICMP packet. code: 0 # The type to use with the ICMP packet. type: 0 # Payload options. payload: # Random payload generation/length. length: # The minimum payload length in bytes (payload is randomly generated). min: 0 # The maximum payload length in bytes (payload is randomly generated). max: 0 # If true, the application will only generate one payload per thread between the minimum and maximum lengths and generate the checksums once. In many cases, this will result in a huge performance gain because generating random payload per packet consumes a lot of CPU cycles depending on the payload length. isstatic: false # If true, the application will read data from the file 'exact' (below) is set to. The data within the file should be in the same format as the 'exact' setting without file support which is hexadecimal and separated by a space (e.g. "FF FF FF FF 59"). isfile: false # If true, will parse the payload (either in 'exact' or the file within 'exact') as a string instead of hexadecimal. isstring: false # If a string, will set the payload to exactly this value. Each byte should be in hexadecimal and separated by a space. For example: "FF FF FF FF 59" (5 bytes of payload data). exact: NULL There are YAML config examples for Packet Batch here. NOTE - The default config path is /etc/pcktbatch/pcktbatch.yaml. This may be changed via the -c and --cfg flags as explained under the Command Line Usage section below. Command Line Usage There are a number of command-line options available for Packet Batch. Each tool has additional command-line usage. With that said, you may override the first sequence through the command-line which allows you to use the tools more easily for single-sequence layouts. Basic Basic command line usage may be found below. Usage: pcktbatch -c <configfile> [-v -h] -c --cfg => Path to YAML file to parse. -l --list => Print basic information about sequences. -v --verbose => Provide verbose output. -h --help => Print out help menu and exit program. First Sequence Override If you wanted to quickly send packets and don't want to create a YAML config file, you may specify command line options to override the first sequence. You must also specify the -z or --cli flag in order to do this. The following command line options are available to override the first sequence. --interface => The interface to send out of. --block => Whether to enable blocking mode (0/1). --count => The maximum amount of packets supported. --time => How many seconds to run the sequence for maximum. --delay => The delay in-between sending packets on each thread. --data => The maximum amount of data (in bytes) we can send. --trackcount => Keep track of count regardless of it being 0 (read Configuration explanation for more information) (0/1). --threads => The amount of threads and sockets to spawn (0 = CPU count). --l4csum => Whether to calculate the layer-4 checksum (TCP, UDP, and ICMP) (0/1). --srcmac => The ethernet source MAC address to use. --dstmac => The ethernet destination MAC address to use. --minttl => The minimum IP TTL to use. --maxttl => The maximum IP TTL to use. --minid => The minimum IP ID to use. --maxid => The maximum IP ID to use. --srcip => The source IP (one range is supported in CIDR format). --dstip => The destination IP. --protocol => The protocol to use (TCP, UDP, or ICMP). --tos => The IP TOS to use. --l3csum => Whether to calculate the IP header checksum or not (0/1). --usrcport => The UDP source port. --udstport => The UDP destination port. --tsrcport => The TCP source port. --tdstport => The TCP destination port. --tsyn => Set the TCP SYN flag (0/1). --tack => Set the TCP ACK flag (0/1). --tpsh => Set the TCP PSH flag (0/1). --trst => Set the TCP RST flag (0/1). --tfin => Set the TCP FIN flag (0/1). --turg => Set the TCP URG flag (0/1). --tcpusesocket => Use TCP cooked socket (0/1). --pmin => The minimum payload data. --pmax => The maximum payload data. --pstatic => Use static payload (0/1). --pexact => The exact payload string. --pfile => Whether to parse a file as the 'pexact' string instead. --pstring => Parse the 'pexact' string or file as a string instead of hexadecimal. Credits @Christian GitHub Organization & Source
-
A program that attaches to the Linux kernel's XDP hook through (e)BPF for fast packet processing and performs basic layer 3/4 forwarding. This program does source port mapping similar to IPTables and NFTables for handling connections. Existing connections are prioritized based off of the connection's packets per nanosecond. This means on port exhaustion, connections with the least packets per nanosecond will be replaced. I believe this is best since connections with higher packets per nanosecond will be more sensitive. Additionally, if the host's network configuration or network interface card (NIC) doesn't support the XDP DRV hook (AKA native; occurs before SKB creation), the program will attempt to attach to the XDP SKB hook (AKA generic; occurs after SKB creation which is where IPTables and NFTables are processed via the netfilter kernel module). You may use overrides through the command-line to force SKB or offload modes. With that said, reasons for a host's network configuration not supporting XDP's DRV hook may be the following. Running an outdated kernel that doesn't support your NIC's driver. Your NIC's driver not yet being supported. Here's a NIC driver XDP support list. With enough Linux kernel development knowledge, you could try implementing XDP DRV support into your non-supported NIC's driver (I'd highly recommend giving this video a watch!). You don't have enough RX/TX queues (e.g. not enabling multi-queue) or your RX/TX queue counts aren't matching. From the information I gathered, it's recommended to have one RX and TX queue per CPU core/thread. You could try learning how to use ethtool and try altering the NIC's RX/TX queue settings (this article may be helpful!). I hope this project helps existing network engineers/programmers interested in utilizing XDP or anybody interested in getting into those fields! High performing routers/packet forwarding and (D)DoS mitigation/prevention are such important parts of Cyber Security and understanding the concept of networking and packet flow on a low-medium level would certainly help those who are pursuing a career in the field ? WARNING - There are still many things that need to be done to this project and as of right now, it only supports IPv4. IPv6 support will be added before official release. As of right now, the program may include bugs and forwarding features aren't yet available. Limitations The default maximum source ports that can be used per bind address is 21 and is set here (you may adjust these if you'd like). We use port range 500 - 520 by default, but this can be configured. At first, I was trying to use most available ports (1 - 65534). However, due to BPF verifier limitations, I had to raise a couple constants inside the Linux kernel and recompile the kernel. I made patches for these and have everything documented here. I am able to run the program with 65534 max ports per bind address without any issues with the custom kernel I built using the patches I made. Though, keep in mind, the more source ports there are available, the more processing the XDP program will have to do when checking for available ports. If you plan to use this for production, I'd highly suggest compiling your own kernel with the constants raised above. 21 maximum source ports per bind address is not much, but unfortunately, the default BPF verifier restrictions don't allow us to go any further currently. The main code that causes these limitations is located here and occurs when we're trying to find the best source port to use for a new connection. There's really no other way to check for the best source port available with the amount of flexibility we have to my understanding since we must loop through all source ports and check the packets per nanosecond value (BPF maps search by key). Requirements Packages You will need make, clang, libelf, and llvm since we use these packages to build the project. Additionally, you will also need libconfig (libconfig-dev is the package on Ubuntu/Debian systems) for parsing the config file. For Ubuntu/Debian, the following should work. apt install build-essential make clang libelf-dev llvm libconfig-dev I'd assume package names are similar on other Linux distros. Mounting The BPF File System In order to use xdpfwd-add and xdpfwd-del, you must mount the BPF file system since the XDP program pins the BPF maps to /sys/fs/bpf/xdpfwd. There's a high chance this is already done for you via iproute2 or something similar, but if it isn't, you may use the following command. mount -t bpf bpf /sys/fs/bpf/ Command Line Usage Basic Basic command line usage includes the following. -o --offload => Attempt to load XDP program with HW/offload mode. If fails, will try DRV and SKB mode in that order. -s --skb => Force program to load in SKB/generic mode. -t --time => The amount of time in seconds to run the program for. Unset or 0 = infinite. -c --config => Location to XDP Forward config (default is /etc/xdpfwd/xdpfwd.conf). -h --help => Print out command line usage. Offload Information Offloading your XDP/BPF program to your system's NIC allows for the fastest packet processing you can achieve due to the NIC processing/forwarding the packets with its hardware. However, there are not many NIC manufacturers that do support this feature and you're limited to the NIC's memory/processing (e.g. your BPF map sizes will be extremely limited). Additionally, there are usually stricter BPF verifier limitations for offloaded BPF programs, but you may try reaching out to the NIC's manufacturer to see if they will give you a special version of their NIC driver raising these limitations (this is what I did with one manufacturer I used). As of this time, I am not aware of any NIC manufacturers that will be able to offload this tool completely to the NIC due to its BPF complexity and loop requirements. To be honest, in the current networking age, I believe it's best to leave offloaded programs to BPF map lookups and minimum packet inspection. For example, a simple BPF layer 2 route table map lookup and then TX the packets back out of the NIC. However, XDP is still very new and I would imagine we're going to see these limitations loosened or lifted in the next upcoming years. This is why I added support for offload mode into this program. XDP Add Program The xdpfwd-add executable which is added to the $PATH via /usr/bin on install accepts the following arguments. -b --baddr => The address to bind/look for. -B --bport => The port to bind/look for. -d --daddr => The destination address. -D --dport => The destination port. -p --protocol => The protocol (either "tcp", "udp", "icmp", or unset for all). -a --save => Save rule to config file. This will add a forwarding rule while the XDP program is running. XDP Delete Program The xdpfwd-del executable which is added to the $PATH via /usr/bin on install accepts the following arguments. -b --baddr => The address to bind/look for. -B --bport => The port to bind/look for. -p --protocol => The protocol (either "tcp", "udp", "icmp", or unset for all). -a --save => Remove rule from config file. This will delete a forwarding rule while the XDP program is running. Configuration The default config file is located at /etc/xdpfwd/xdpfwd.conf and uses the libconfig syntax. Here's an example config using all of its current features. interface = "ens18"; // The interface the XDP program attaches to. // Forwarding rules array. forwarding = ( { bind = "10.50.0.3", // The bind address which incoming packets must match. bindport = 80, // The bind port which incoming packets must match. protocol = "tcp", // The protocol (as of right now "udp", "tcp", and "icmp" are supported). Right now, you must specify a protocol. However, in the future I will be implementing functionality so you don't have to and it'll do full layer-3 forwarding. dest = "10.50.0.4", // The address we're forwarding to. destport = 8080 // The port we're forwarding to (if not set, will use the bind port). }, ... ); Credits @Christian - Creator GitHub Repository
- 1 reply
-
- 3
-

-
A Discord bot that allows for global chat between Discord servers in certain channels. Used for an old non-continued project called Unnamed which was going to be a series of Discord servers (helped by @Bue.). Requirements The Discord.py package is required in order to use this bot. You may install this via the following command. python3 -m pip install -U discord.py Command Line Usage You may specify the settings JSON (used for the bot token, etc) and the SQLite DB location within the command line. The default settings location is /etc/dgc/settings.json and the default SQLite DB location is /etc/dgc/dgc.db. The following are examples of how to set these in the program. python3 src/main.py cfg=/home/cdeacon/settings.json sqlite=/home/cdeacon/dgc.db Config The config file is in JSON format and the following keys are supported. BotToken - The Discord bot token. Please retrieve this from the Discord Developers page for your bot. BotMsgStayTime - When the bot replies to a command in a text channel, delete the bot message this many seconds after (default - 10.0 seconds). UpdateTime - How often to update the channel and web hook URL cache in seconds (default - 60.0 seconds). Bot Commands The command prefix is !. You must execute these commands inside of a text channel of the guild you want to modify. You must also be an administrator in order to use these commands. dgc_linkchannel !dgc_linkchannel <channel ID> Adds a channel to the linked global chat. If the channel ID is left blank, it will choose the channel the message was sent in. dgc_unlinkchannel !dgc_unlinkchannel <channel ID> Unlinks a channel to the linked global chat. dgc_updatehook !dgc_updatehook <webhook URL> Updates the web hook that messages send to within the current guild. This must be pointed towards the correct channel ID set with dgc_linkchannel. Installing You may use make install within this directory to create the /etc/dgc/ directory and copy settings.json.example to /etc/dgc/settings.json. Please configure the settings.json file to your needs. Other than that, the needed SQLite tables are created if they don't exist when the Python program is started. However, if need to be, here is the current table structure. CREATE TABLE IF NOT EXISTS `channels` (guildid integer PRIMARY KEY, channelid integer, webhookurl text) Starting As of right now, you'll want to use python3 against the src/main.py file. Something like the following should work. python3 src/main.py If there's a better way to handle this, please let me know. Credits @Christian GitHub Repository & Source
-
A small open-source Discord Bot written in Python which allows you to react to messages and obtain a role. This is being used in a personal Discord server of mine. Please note this is one of my first official Python projects and I went into this without much knowledge of Python itself along with no experience with the Discord.py wrapper. Therefore, there's a chance a lot of this code can be improved. The project uses SQLite to keep track of messages, reactions, reaction definitions, etc. At the moment, you may use bot commands to create/edit/delete messages along with assign/remove reactions. I understand this is probably less convenient than having everything handled in a web panel. However, I do not have any web experience with Python specifically at the moment and this project was aimed to suit the needs of my personal Discord server (although, any other guild should be able to use it without any issues and the bot itself should be able to handle multiple guilds). In regards to performance, one - three SQL queries are performed during the following events (likely a SELECT query followed by an INSERT or UPDATE query). A reaction is added. A reaction is removed. When one of the bot commands are executed. However, there is a cooldown implemented which should help prevent a single user from intentionally hammering resources. With that said, due to the latency when sending a Discord message, I do doubt you'd be able to hammer the resources even if a single user were to spam without the cooldown. Additionally, if a user is spamming these commands, I believe you have a bigger issue on your hands. I did think about creating a background task to update specific lists such as the allowed roles list from each guild which is stored in SQLite (permissions table). However, technically, this would result in everything not being completely accurate and I don't believe the pros outweigh the cons in this case when a cooldown is being considered. Requirements The Discord.py package is required in order to use this bot. You may install this via the following command. python3 -m pip install -U discord.py Command Line Usage You may specify the settings JSON (used for the bot token, etc) and the SQLite DB location within the command line. The default settings location is /etc/dcr/settings.json and the default SQLite DB location is /etc/dcr/dcr.db. The following are examples of how to set these in the program. python3 src/main.py cfg=/home/cdeacon/settings.json sqlite=/home/cdeacon/dcr.db Config The config file is in JSON format and the following keys are supported. BotToken - The Discord bot token. Please retrieve this from the Discord Developers page for your bot. Cooldown - The cooldown in-between adding reactions and executing bot commands for the specific user in seconds (default - 1.0 second). BotMsgStayTime - When the bot replies to a command in a text channel, delete the bot message this many seconds after (default - 10.0 seconds). Bot Commands The command prefix is !. You must execute these commands inside of a text channel of the guild you want to modify. dcr_addrole !dcr_addrole <role name> Adds a role to the allowed roles list. If the user doesn't exist in this role, they cannot execute bot commands. dcr_delrole !dcr_delrole <role name> Removes a role from the allowed roles list. dcr_listroles !dcr_listroles Lists all of the allowed roles. dcr_addmsg !dcr_addmsg <max reactions> <contents> <message ID> Adds a message for people to react on. Max reactions indicates the maximum reactions a user can select at once. Contents indicates the message's contents (you may use the \n character for new lines). If the message's contents are set to "SKIP", it will not submit a new message nor edit the contents of the message. This is useful if you want to add reactions for a non-bot message. Message ID is optional and is only used if you want to add an existing message instead of a new one which may be easier for those that want to modify the message. dcr_editmsg !dcr_editmsg <message ID> <max reactions> <contents> Modifies a message. Message ID indicates the message ID you can obtain from Discord's Developer Mode. Max reactions indicates the new maximum reactions number (or enter "SKIP" to skip this update). Contents indicates the new contents for the message (or "SKIP" to skip this update). dcr_delmsg !dcr_delmsg <message ID> Removes a message by ID from the database and on the guild itself. Message ID indicates the message ID you can obtain from Discord's Developer Mode. dcr_addreaction !dcr_addreaction <message ID> <reaction> <role name> Adds a reaction to a message for others to start reacting to in order to obtain roles. Message ID indicates the message ID you can obtain from Discord's Developer Mode. Reaction indicates the reaction (use the reaction itself, not the text/code). Role name indicates the name of the role the user will receive when reacting or get removed when removing a reaction. dcr_delreaction !dcr_delreaction <message ID> <reaction> Removes a reaction from a message. Message ID indicates the message ID you can obtain from Discord's Developer Mode. Reaction indicates the reaction (use the reaction itself, not the text/code). dcr_clearuser !dcr_clearuser <user ID> Removes all rows from the reactions table for a certain user ID. User ID indicates the user's ID you can obtain from Discord's Developer Mode. Installing You may use make install within this directory to create the /etc/dcr/ directory and copy settings.json.example to /etc/dcr/settings.json. Please configure the settings.json file to your needs. Other than that, the needed SQLite tables are created if they don't exist when the Python program is started. However, if need to be, here is the current table structure. CREATE TABLE IF NOT EXISTS `reactions` (id integer PRIMARY KEY AUTOINCREMENT, userid integer, msgid integer, guildid integer, reaction text) CREATE TABLE IF NOT EXISTS `reactionroles` (id integer PRIMARY KEY AUTOINCREMENT, msgid integer, guildid integer, reaction text, roleid integer) CREATE TABLE IF NOT EXISTS `messages` (id integer PRIMARY KEY AUTOINCREMENT, msgid integer, guildid integer, maxreactions integer, contents text) CREATE TABLE IF NOT EXISTS `permissions` (guildid integer PRIMARY KEY, roles text) Starting As of right now, you'll want to use python3 against the src/main.py file. Something like the following should work. python3 src/main.py If there's a better way to handle this, please let me know. Credits @Christian GitHub Repository & Source
-
A stateless firewall that attaches to the Linux kernel's XDP hook through (e)BPF for fast packet processing. This firewall is designed to read filtering rules based off of a config file on disk and filter incoming packets. Both IPv4 and IPv6 are supported! The protocols currently supported are TCP, UDP, and ICMP. With that said, the program comes with accepted and dropped/blocked packet statistics which may be disabled if need to be. Additionally, if the host's network configuration or network interface card (NIC) doesn't support the XDP DRV hook (AKA native; occurs before SKB creation), the program will attempt to attach to the XDP SKB hook (AKA generic; occurs after SKB creation which is where IPTables and NFTables are processed via the netfilter kernel module). You may use overrides through the command-line to force SKB or offload modes. With that said, reasons for a host's network configuration not supporting XDP's DRV hook may be the following. Running an outdated kernel that doesn't support your NIC's driver. Your NIC's driver not yet being supported. Here's a NIC driver XDP support list. With enough Linux kernel development knowledge, you could try implementing XDP DRV support into your non-supported NIC's driver (I'd highly recommend giving this video a watch!). You don't have enough RX/TX queues (e.g. not enabling multi-queue) or your RX/TX queue counts aren't matching. From the information I gathered, it's recommended to have one RX and TX queue per CPU core/thread. You could try learning how to use ethtool and try altering the NIC's RX/TX queue settings (this article may be helpful!). I hope this project helps existing network engineers/programmers interested in utilizing XDP or anybody interested in getting into those fields! (D)DoS mitigation/prevention is such an important part of Cyber Security and understanding the concept of networking and packet flow on a low-medium level would certainly help those who are pursuing a career in the field ? Command Line Usage The following command line arguments are supported: --config -c => Location to config file. Default => /etc/xdpfw/xdpfw.conf. --offload -o => Tries to load the XDP program in hardware/offload mode (please read Offload Information below). --skb -s => Forces the program to load in SKB mode instead of DRV. --time -t => How long to run the program for in seconds before exiting. 0 or not set = infinite. --list -l => List all filtering rules scanned from config file. --help -h => Print help menu for command line options. Offload Information Offloading your XDP/BPF program to your system's NIC allows for the fastest packet processing you can achieve due to the NIC dropping the packets with its hardware. However, for one, there are not many NIC manufacturers that do support this feature and you're limited to the NIC's memory/processing (e.g. your BPF map sizes will be extremely limited). Additionally, there are usually stricter BPF verifier limitations for offloaded BPF programs, but you may try reaching out to the NIC's manufacturer to see if they will give you a special version of their NIC driver raising these limitations (this is what I did with one manufacturer I used). As of this time, I am not aware of any NIC manufacturers that will be able to offload this firewall completely to the NIC due to its BPF complexity. To be honest, in the current networking age, I believe it's best to leave offloaded programs to BPF map lookups and minimum packet inspection. For example, a BPF blacklist map lookup for malicious source IPs or ports. However, XDP is still very new and I would imagine we're going to see these limitations loosened or lifted in the next upcoming years. This is why I added support for offload mode on this firewall. Configuration File Options Main interface => The interface for the XDP program to attach to. updatetime => How often to update the config and filtering rules. Leaving this at 0 disables auto-updating. nostats => If true, no accepted/blocked packet statistics will be displayed in stdout. Filters Config option filters is an array. Each filter includes the following options. enabled => If true, this rule is enabled. action => What action to perform against the packet if matched. 0 = Block. 1 = Allow. srcip => The source IP address the packet must match (e.g. 10.50.0.3). dstip => The destination IP address the packet must match (e.g. 10.50.0.4). srcip6 => The source IPv6 address the packet must match (e.g. fe80::18c4:dfff:fe70:d8a6). dstip6 => The destination IPv6 address the packet must match (e.g. fe80::ac21:14ff:fe4b:3a6d). min_ttl => The minimum TTL (time to live) the packet must match. max_ttl => The maximum TTL (time to live) the packet must match. max_len => The maximum packet length the packet must match. This includes the entire frame (ethernet header, IP header, L4 header, and data). min_len => The minimum packet length the packet must match. This includes the entire frame (ethernet header, IP header, L4 header, and data). tos => The TOS (type of service) the packet must match. pps => The maximum packets per second a source IP can send before matching. bps => The maximum amount of bytes per second a source IP can send before matching. blocktime => The time in seconds to block the source IP if the rule matches and the action is block (0). Default value is 1. TCP Options TCP options exist in the main filter array and start with tcp_. Please see below. tcp_enabled => If true, check for TCP-specific matches. tcp_sport => The source port the packet must match. tcp_dport => The destination port the packet must match. tcp_urg => If true, the packet must have the URG flag set to match. tcp_ack => If true, the packet must have the ACK flag set to match. tcp_rst => If true, the packet must have the RST flag set to match. tcp_psh => If true, the packet must have the PSH flag set to match. tcp_syn => If true, the packet must have the SYN flag set to match. tcp_fin => If true, the packet must have the FIN flag set to match. tcp_ece => If true, the packet must have the ECE flag set to match. tcp_cwr => If true, the packet must have the CWR flag set to match. UDP Options UDP options exist in the main filter array and start with udp_. Please see below. udp_enabled => If true, check for UDP-specific matches. udp_sport => The source port the packet must match. udp_dport => The destination port the packet must match. ICMP Options ICMP options exist in the main filter array and start with icmp_. Please see below. icmp_enabled => If true, check for ICMP-specific matches. icmp_code => The ICMP code the packet must match. icmp_type => The ICMP type the packet must match. Everything besides the main enabled and action options within a filter are not required. This means you do not have to define them within your config. Note - As of right now, you can specify up to 100 maximum filters. This is due to BPF's max jump limit within the while loop. Configuration Example Here's an example of a config. interface = "ens18"; updatetime = 15; filters = ( { enabled = true, action = 0, udp_enabled = true, udp_dport = 27015 }, { enabled = true, action = 1, tcp_enabled = true, tcp_syn = true, tcp_dport = 27015 }, { enabled = true, action = 0, icmp_enabled = true, icmp_code = 0 }, { enabled = true, action = 0, srcip = "10.50.0.4" } ); Building & Installation Before building, ensure the libconfig-dev package is installed along with necessary building tools such as llvm, clang, and libelf-dev. For Debian/Ubuntu, you can install this with the following as root: # Install dependencies. apt-get install libconfig-dev llvm clang libelf-dev build-essential -y You can use git and make to build this project. The following should work: # Clone repository via Git. Use recursive flag to download LibBPF sub-module. git clone --recursive https://github.com/gamemann/XDP-Firewall.git # Change directory to repository. cd XDP-Firewall # Build project and install as root via Sudo. make && sudo make install Notes BPF For/While Loop Support This project requires for/while loop support with BPF. Older kernels will not support this and output an error such as the following. libbpf: load bpf program failed: Invalid argument libbpf: -- BEGIN DUMP LOG --- libbpf: back-edge from insn 113 to 100 libbpf: -- END LOG -- libbpf: failed to load program 'xdp_prog' libbpf: failed to load object '/etc/xdpfw/xdpfw_kern.o' It looks like BPF while/for loop support was added in kernel 5.3. Therefore, you'll need kernel 5.3 or above for this program to run properly. Will You Make This Firewall Stateful? There is a possibility I may make this firewall stateful in the future when I have time, but this will require a complete overhaul along with implementing application-specific filters. With that said, I am still on contract from my previous employers for certain filters of game servers. If others are willing to contribute to the project and implement these features, feel free to make pull requests! You may also be interested in this awesome project called FastNetMon! Credits @Christian GitHub Repository
-
An application made in Go (latest version works) for Rust servers operating with Pterodactyl (latest API version works). This application automatically wipes server(s) based off of cron jobs. The program is aimed to be as flexible as possible. With that said, there are many features including the following. Allow rotating of world settings (map/level, world size, and world seed). Allow automatically changing the host name on each wipe with format support (including option replacements like {day_two} and {month_two}). Deletion of files with the option to except specific types (e.g. don't delete player data such as states, identities, tokens, and more). A flexible configuration and uses a cron job system (support for multiple cron jobs per server). Support for retrieving servers automatically from Pterodactyl API. Pterodactyl egg variable overrides to allow others to change these settings without having access to the application's file system. Pre and post wipe hooks (sends POST data to specific endpoints that can be used for Discord web hooks for example). Note - This is only tested on Linux. However, technically it should work for Windows as well. Command Line Usage The below is the command line usage from the help menu for this program. Help Options -cfg= --cfg -cfg <path> > Path to config file override. -l --list > Print out full config. -v --version > Print out version and exit. -h --help > Display help menu. Configuration All configuration is done inside a config file on disk via JSON or through environmental variable overrides. The default config path is /etc/raw/raw.conf and may be changed via the -cfg command line flag. Any wipe-specific configuration at the top-level of the configuration is used as the default values for each server. Each server may override these by specifiying the same key => value pairs inside of the server array. When the program is ran, but no configuration file is found, it will attempt to create the file (likely requiring root privileges by default if trying to create inside of /etc/, however). The below are all JSON settings along with their default values, but with added comments. Remember that JSON does not support comments. Therefore, copying the below contents with comments will result in errors. This is why it's recommended to allow the program to create a default configuration file. { // The URL to the panel (make sure to include a trailing /). Ex: http://ptero.something.internal/ "apiurl": "", // The Pterodactyl client token (should start with "ptlc_"). Create under user account settings in Pterodactyl panel. "apitoken": "", // Debug level from 0 - 4. "debuglevel": 1, // The application token (required for automatically adding servers from Pterodactyl). "apptoken": "", // Automatically add servers from Pterodactyl (servers require 'WORLD_SEED' and 'HOSTNAME' environmental variables). "autoaddservers": false, // Path starting from /home/container to the server files we need to delete (should be /server/rust with default Rust egg). "pathtoserverfiles": "/server/rust", // Timezone for Cron jobs to run with. "timezone": "America/Chicago", // Either a single string or a slice/array of strings representing when the server should be wiped and processed via Cron format. // I would recommend using a Cron generator (there are many online). // With that said, the default value wipes at 3:30 PM every Thursday. "cronstr": "30 15 * * 4", // Whether to delete map files (includes *.map and *.sav files). "deletemap": true, // Whether to delete player blueprints (includes any files with blueprints in the file name). "deletebp": true, // Whether to delete deaths (includes any files with deaths in the file name). "deletedeaths": true, // Whether to delete states (includes any files with states in the file name). "deletestates": true, // Whether to delete identities (includes any files with identities in the file name). "deleteidentities": true, // Whether to delete tokens (includes any files with tokens in the file name). "deletetokens": true, // Whether to merge the top-level additional files array and the server-specific files array. "deletefilesmerge": false, // Additional deletion of files using an array with the array items including "root" as the directory path starting from /home/container (make sure to include beginning /) and another array of strings for file deletion (wildcards included). Ex: [{"root": "/server/rust", "files": [".log"]}] "deletefiles": null, // Whether to delete server data/files (includes any files with sv.files in the file name). "deletesv": true, // Whether to change the world info. "changeworldinfo": false, // An array with the map, world size, and world seed. (e.g. [{"map": "Procedural Map", "worldsize": 4000, "worldseed": 9213913}]) "worldinfo": null, // World info pick type (1 = pick the next world, otherwise, pick a random world). "worldinfopicktype": 1, // Whether to merge world information arrays. "worldinfomerge": false, // Whether to change the hostname. "changehostname": true, // The hostname format. // Would recommend looking here for a cheatsheet on Golang's format library -> https://gosamples.dev/date-time-format-cheatsheet/ // Replacements include: // {seconds_left} = Amount of seconds left until next wipe (only valid for warning messages). // // {tz_one} = Timezone in TTT format (e.g. MST). // {tz_two} = Timezone offset in ±hhmm format (e.g. +0100). // {tz_three} = Timezone offset in ±hh format (e.g. +01). // // {month_str_short} = Month in TTT format (e.g. Jan). // {month_str_long} = Full month string (e.g. January). // // {week_day_str_short} = Week day in TTT format (e.g. Mon). // {week_day_str_long} = Full week day string (e.g. Monday). // // {year_one} = Year in TT format (e.g. 22). // {year_two} = Full year (e.g. 2022). // // {month_one} = Month in TT format (e.g. 01). // {month_two} = Month in T format (e.g. 1). // {month_three} = Month in _T format (e.g. 1). // // {day_one} = Day in TT format (e.g. 01). // {day_two} = Day in T format (e.g. 1). // {day_three} = Day in _T format (e.g. 1). // // {hour_one} = Hour in TT 12 HR format (e.g. 05). // {hour_two} = Hour in T 12 HR format (e.g. 5). // {hour_three} = Hour in TT 24 HR format (e.g. 17). // // {min_one} = Minute in TT format (e.g. 06). // {min_two} = Minute in T format (e.g. 6). // // {sec_one} = Second in TT format (e.g. 07). // {sec_two} = Second in T format (e.g. 7). // // {mark_one} = 12-HR mark as TT format (e.g. PM or AM). // {mark_two} = 12-HR mark as tt format (e.g. pm or am). "hostname": "Vanilla | FULL WIPE {month_two}/{day_two}", // Whether to merge both server-specific and global warning messages. "mergewarnings": false, // Warning messages list "warningmessages": [ { // The prewarn time (e.g. this would warn one second before wipe whereas if the warning time was 10, it would warn 10 seconds before wipe time). "warningtime": 1, // The message (use formatting from hostname documentation). "message": "Wiping server in {seconds_left} seconds. Please join back!" }, { "warningtime": 2, "message": "Wiping server in {seconds_left} seconds. Please join back!" }, { "warningtime": 3, "message": "Wiping server in {seconds_left} seconds. Please join back!" }, { "warningtime": 4, "message": "Wiping server in {seconds_left} seconds. Please join back!" }, { "warningtime": 5, "message": "Wiping server in {seconds_left} seconds. Please join back!" }, { "warningtime": 6, "message": "Wiping server in {seconds_left} seconds. Please join back!" }, { "warningtime": 7, "message": "Wiping server in {seconds_left} seconds. Please join back!" }, { "warningtime": 8, "message": "Wiping server in {seconds_left} seconds. Please join back!" }, { "warningtime": 9, "message": "Wiping server in {seconds_left} seconds. Please join back!" }, { "warningtime": 10, "message": "Wiping server in {seconds_left} seconds. Please join back!" } ], // Hooks (submits POST data in JSON with "id", "uuid", "identifier", "name", "ip", and "port" to the hook string/URL). The auth string for each is set to the "Authorization" header (e.g. "Bearer xxxxx"). // Pre wipe hook. prehook: "", prehookauth: "", // Post wipe hook. posthook: "", posthookauth: "", // Server list (null by default). "servers": null } The servers array includes the following. { "servers": [ { // Whether to enable the server or not (enabled by default). "enabled": true, // The number ID of the server (should be retrieved automatically if the server exists). "id": 0, // The (short) identifier of the server. Characters before the first "-" in the long UUID. "uuid": "", // Overrides (retrieve definition from top-level comments above). "apiurl": "", "apitoken": "", "debuglevel": 1, "pathtoserverfiles": "/server/rust", "timezone": "America/Chicago", "cronstr": "30 15 * * 4", "deletemap": true, "deletebp": true, "deletedeaths": true, "deletestates": true, "deleteidentities": true, "deletetokens": true, "deletefilesmerge": false, "deletefiles": null, "deletesv": true, "changeworldinfo": false, "worldinfo": null, "worldinfopicktype": 1, "worldinfomerge": false, "changehostname": true, "hostname": "Vanilla | FULL WIPE {month_two}/{day_two}", "mergewarnings": false, "warningmessages": null, // Extras. // Wipe server when the program is first started. "wipefirst": false } ... ] } Note - When writing to the default file after creation, it will try to make the JSON data pretty (AKA pretty print by idents). Environmental Overrides With Auto-Added Servers There are environmental overrides for servers that are added from the Pterodactyl API. This allows you to distribute access easier from within the Pterodactyl panel itself. With that said, the file data/egg-rustraw.json file in this repository is an exported egg that has the standard Rust egg settings from Pterodactyl along with the additional RAW settings. If you import this egg into Pterodactyl under Rust and change the server's egg in the administrator settings, it will easily migrate all existing variable settings over including the Rust egg's default variables. Each variable is also parsed as a string within the application's code. For true/false, use the 1/0 integers respectfully. The following is a list of environmental names you can create variables within Pterodactyl Nests/Eggs for overrides. RAW_ENABLED - Enabled override. RAW_PATHTOFILES - Path to files override. RAW_TIMEZONE - Timezone override. RAW_CRONMERGE - Cron merge override. RAW_CRONSTR - Cron string override (this is a special case, cron string(s) can be a single string or a string array as a JSON string (e.g. ["*/5 * * * *", "*/2 * * * *"])). RAW_DELETEMAP - Delete map override. RAW_DELETEBP - Delete blueprints override. RAW_DELETEDEATHS - Delete deaths override. RAW_DELETESTATES - Delete states override. RAW_DELETEIDENTITIES - Delete identities override. RAW_DELETEFILESMERGE - Whether to merge additional deletion of files override (top-level config and server-specific). RAW_DELETEFILES - Additional files to delete override. (e.g. [{"root": "/server/rust", "files": [".log"]}] as a string). RAW_DELETESV - Delete server files/data override. RAW_CHANGEWORLDINFO - Change world info override. RAW_WORLDINFO - World info override. An array with the map, world size, and world seed. (e.g. [{"map": "Procedural Map", "worldsize": 4000, "worldseed": 9213913}] as a string). RAW_WORLDINFOPICKTYPE - Change world info pick type override. RAW_WORLDINFOMERGE - Change world info merge override. RAW_CHANGEHOSTNAME - Change hostname override. RAW_HOSTNAME - Hostname override. RAW_MERGEWARNINGS - Merge warnings override. RAW_WARNINGMESSAGES - Warning messages override (another special case, this should be a JSON string of the normal warningmessages JSON item). (e.g. [{"warningtime": 5, "message": "{seconds_left} until wipe!"}] as a string). RAW_WIPEFIRST - Wipe first override. Building And Running Project (Manually) Building the project is simple. We only require git and Go. # Clone repository. git clone https://github.com/gamemann/Rust-Auto-Wipe.git # Change directory to repository. cd Rust-Auto-Wipe/ # Build using Go into `raw` executable. This will also retrieve needed packages such as Cronv3. go build -o raw Using Makefile as described below is my personal recommendation on installing this application for Linux-based systems. Using Makefile + Systemd (Recommended) You may also use a Makefile I made to build the application and install a Systemd file. # Build project (go build -o raw). make # Install `rawapp` (/usr/bin/rawapp) and Systemd process. sudo make install To have the application run on startup, and/or in the background, you may do the following. # Reload Systemd daemon (may be needed after install of Systemd service). sudo systemctl daemon-reload # Enable (on startup) and start service. sudo systemctl enable --now raw # Start service. sudo systemctl start raw # Restart service. sudo systemctl restart raw # Stop service. sudo systemctl stop raw # Disable (on startup) and stop service. sudo systemctl disable --now raw Credits @Christian GitHub Repository & Source Code